Formatting Text Files before Importing
You should ensure a text file is correctly formatted (contains the information in the correct order) before
importing.
The first lines in the text file should be:
- format
- 1 46 1 0 1
The numbers in the second line should be separated by tabs. These numbers (parameters) inform the import procedure about the contents of the import file, as follows:
- Date Order
- The first parameter tells the import procedure what date format you have used in the text file. You can use the following values:
- 0
- Month/Day/Year
- 1
- Day/Month/Year
- 2
- Year/Month/Date
- Decimal Character
- The second parameter uses ASCII codes to tell the import procedure what decimal character you have used in the text file. Typical values are:
- 44
- comma
- 46
- full stop
- Machine Mode
- Use the third parameter to specify the platform on which you created the text file, as follows:
- 0
- Macintosh, AIX, iSeries
- 1
- Windows, Linux
The import procedure will use this information for string conversion if the last parameter (String Type) is 0.
- Replace
- This parameter tells the import procedure what to do if information in the text file duplicates what is already in the database.
- 0
- Any duplicate information in the text file will not be imported. Records in the database will not be replaced.
- 1
- Duplicate information in the text file will be imported, overwriting existing records in the database. This applies to entire records. For example, there is an existing Customer 001 in the database with the name Customer A and Payment Terms 30 days, and in the import file Customer 001 has the name Customer AA and no Payment Terms. The import procedure will overwrite the entire record for Customer 001, so the result will be that it has the name Customer AA and no Payment Terms. Records in the database with no duplicate in the text file will not be touched.
- String Type
- Use the final parameter to specify the character set used in the text file:
- 0
- The text file contains characters belonging to a single character set (e.g. ASCII, KOI-8R [Russian Cyrillic], ISO-8859-1 [Western European]).
- 1
- The text file contains Unicode characters.
The format line in the text file should be followed by at least one blank line (the exact number of blank lines is unimportant, providing there is at least one), then by the name of the register into which you are importing (not case sensitive), then by the individual records. The field delimiter should be the Tab character, and the record delimiter should be a double carriage return.
For example, we need to import into the sample Stock Count register shown below:
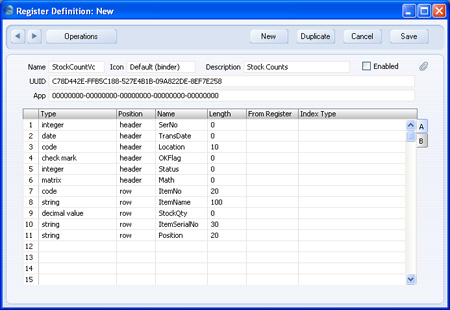
The text file should be constructed as follows:
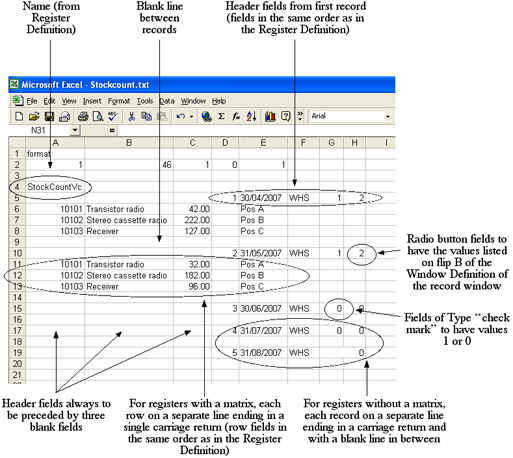
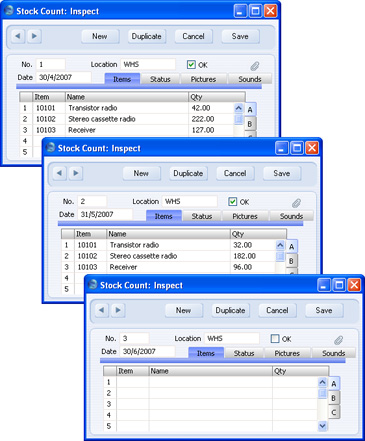
This text file will cause five new records to be imported to the example Stock Count register, the first three of which are shown below:
In this example, the Register Definition has been constructed so that the header fields are all listed first, followed by all the row fields. It may be that the header and row fields are not divided in this way, but are jumbled up (perhaps new fields were added after the register had been in use). In this case, you should still keep the header information together in the text file, and keep all the row information together. For example, if a new header field is added to the Register Definition on row 12, information to be imported to this field should be placed in cells I5, I10, I15, I17 and I19 in the text file/spreadsheet.
If you do not want new records to be created by the import process, but instead you want to overwrite existing records, you will need to change the Replace parameter in the format line as described above. The text file should be as follows:
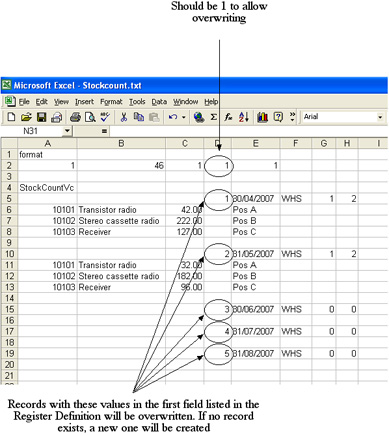
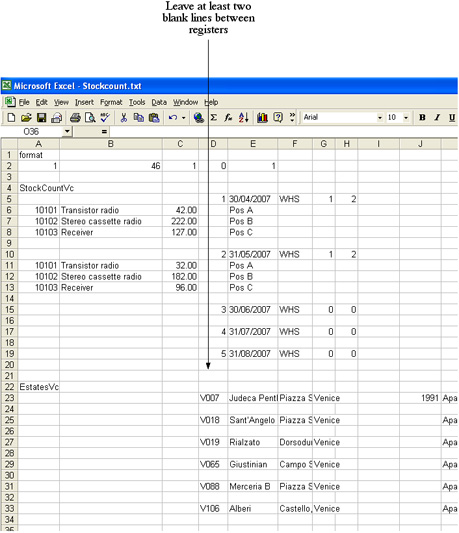
If you need to import information to more than one register, leave at least two blank lines before the name of the second register:
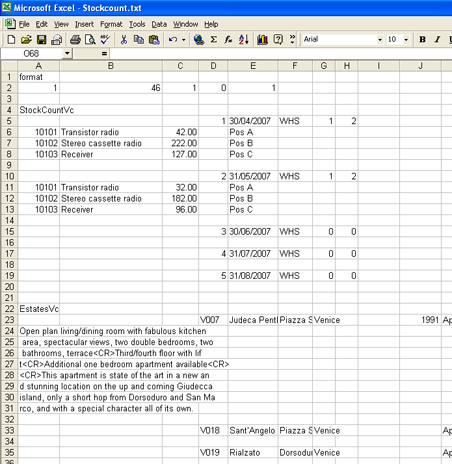
If a register contains a field of Type "text field", place the text on a new line and break it up into lines of no more than 255 characters. Separate each line with a single carriage return. If the text contains any carriage returns, replace them with < CR >. Similarly, replace tabs with < TB > and line feeds with < LF > (without spaces in each case):
---
See also:
Go back to:
See also: